图
图(Graph)
这个话题已经有个辅导文章
图看上去像下图:
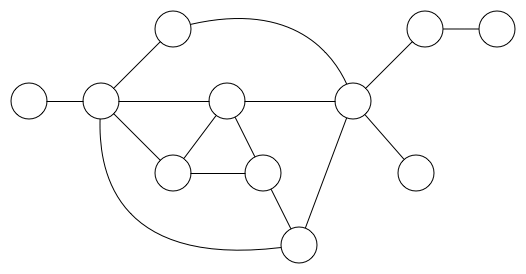
在计算机科学中,图形被定义为一组点和与之配对的一组边。 点用圆圈表示,边是它们之间的线。 边链接点与点。
注意: 点有时称为“节点”,边称为“链接”。
图可以代表社交网络。 每个人都是一个点,彼此认识的人通过边链接。 下面是一个有点历史不准确的例子:

图具有各种形状和大小。 当为每个边分配正数或负数,边可以具有权重。 考虑一个代表飞机航班的图示例。 城市用点表示,而航班用边表示。 然后,边权重可以描述航班时间或票价。
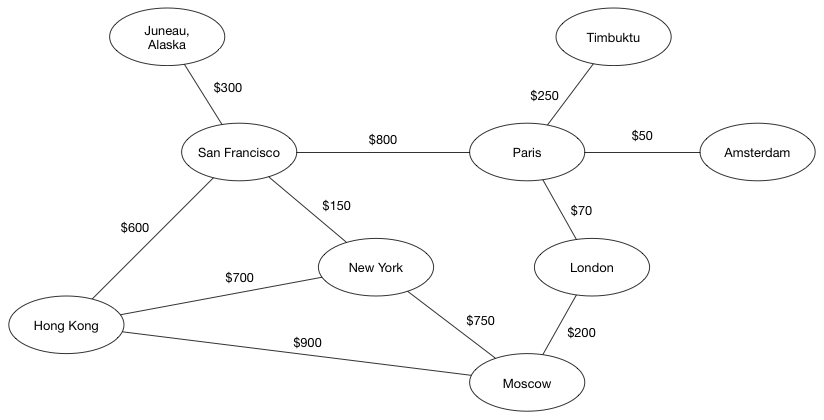
有了这个假想的航线,从旧金山(San Francisco)飞往莫斯科(Moscow),经过纽约(New York)这条航线是最便宜的。
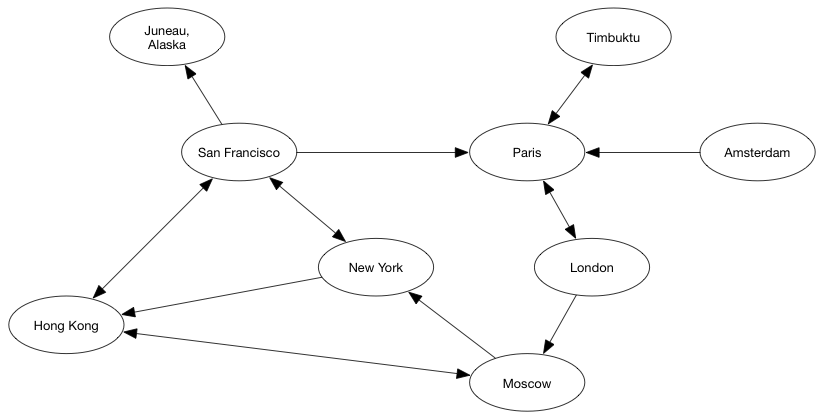
边也可以有向的。 在上面提到的例子中,边是无向的。 例如,如果阿达(Ada)可以到达查尔斯(Charles),那么查尔斯也可以到达阿达。 另一方面,有向边意味着单向关系。 从点X到点Y的有向边链接X到Y,但Y不能到X.
从航班的例子来看,从旧金山到阿拉斯加的朱诺( Juneau, Alaska)的有向的边表明从旧金山到朱诺的航班,但不是从朱诺到旧金山(我想这意味着你正在走回头路)的航班。
以下也是图:
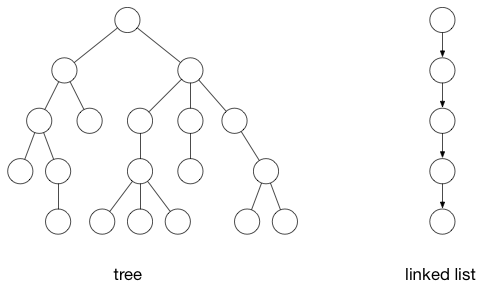
左边是树结构,右边是链表。 它们可以被视为形式更简单的图。 它们都有点(节点)和边(链接)。
第一个图(译注:文章的第一个图)包括循环,您可以从点开始,沿着路径,然后返回到原始点。 树是没有这种循环的图。
另一种常见类型的图是有向无环图(DAG, directed acyclic graph):
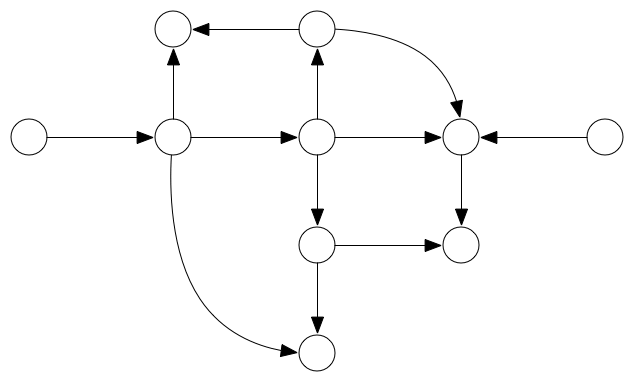
像树一样,这个图没有任何循环(无论你从哪里开始,都没有回到起始点的路径),但是这个图的定向边的形状不一定形成层次结构。
为什么使用图?
也许你耸耸肩膀思考,有什么大不了的? 好吧,事实证明图是一种有用的数据结构。
如果您遇到编程问题,您可以将数据表示为点和边,那么您可以将你的问题绘制为图形并使用众所周知的图算法,例如广度优先搜索或深度优先搜索找到解决方案。
例如,假设您有一个任务列表,其中某些任务必须先等待其他任务才能开始。 您可以使用非循环有向图对此进行建模:
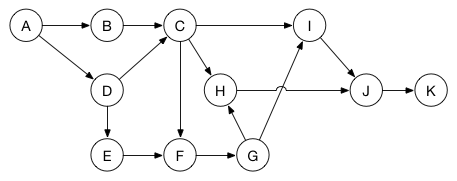
每个点代表一个任务。 两个点之间的边意味着必须在目标任务开始之前必须完成源任务。 例如,任务C在B和D完成之前无法启动,B和D可以在A完成之前启动。
现在使用图表表示问题,您可以使用深度优先搜索来执行拓扑排序。 这将使任务处于最佳顺序,以便最大限度地减少等待任务完成所花费的时间。 (这里可能的一个顺序是A,B,D,E,C,F,G,H,I,J,K。)
无论何时遇到困难的编程问题,请问自己,“如何使用图表示此问题?” 图是你所有数据之间特定关系。 诀窍在于如何定义“关系”。
如果您是音乐家,您可能会喜欢这张图:
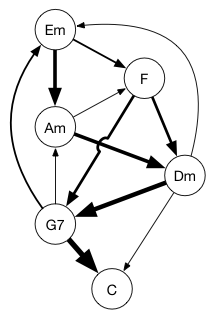
这些点是C大调的和弦。 边 —— 和弦之间的关系 —— 代表可能一个和弦跟随另一个和弦。 这是一个有向图,因此箭头的方向显示了如何从一个和弦转到下一个和弦。 它也是一个权重图,其中边的权重 —— 这里用线条粗细描绘 —— 显示了两个和弦之间的强关系。 正如你所看到的,G7和弦很可能后跟一个C和弦,也可能是一个Am和弦。
您可能在不知道图时,已经使用过图了。 您的数据模型也是图(来自Apple的Core Data文档):
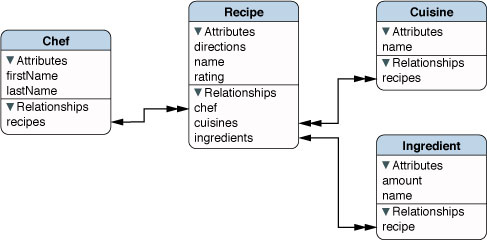
程序员使用的另一个常见图是状态机(state machine),其中边描述了状态之间转换的条件。 这是一个模拟我的猫的状态机:
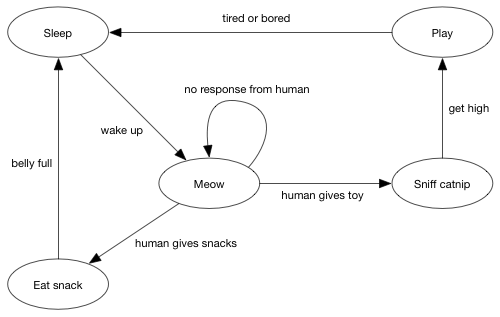
图很棒。 Facebook从他们的社交图中赚了大钱。 如果要学习任何数据结构,则必须选择图和大量标准图算法。
哦,我的点和边!
理论上,图只是一堆点和边对象,但是如何在代码中描述它?
有两种主要策略:邻接表和邻接矩阵。
邻接表(Adjacency List)。在邻接表实现中,每个点存储一个从这个点出发的所有边的列表。例如,如果点A具有到点B,C和D的边,则点A将具有包含3个边的列表。
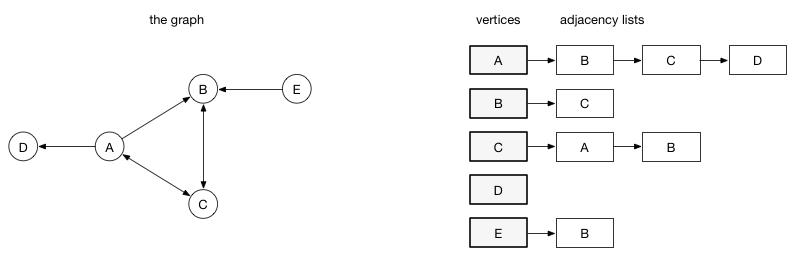
邻接表描述了传出边。 A具有到B的边,但是B没有返回到A的边,因此A不出现在B的邻接表中。在两个点之间找到边或权重成本可能很高,因为没有随机访问边。 您必须遍历邻接表,直到找到它为止。
邻接矩阵(Adjacency Matrix)。 在邻接矩阵实现中,具有表示顶点的行和列的矩阵存储权重以指示顶点是否连接以及权重。 例如,如果从点A到点B有一个权重为5.6的有向边,那么点A行和B列交叉的值为5.6:
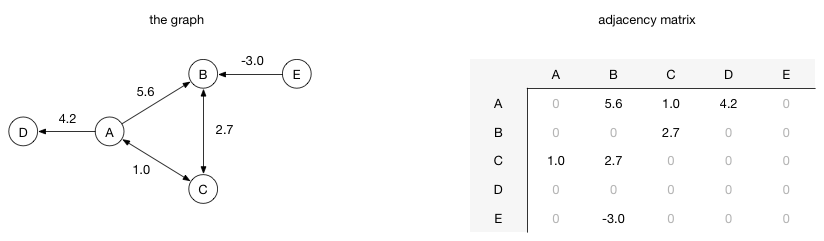
向图添加另一个点是成本很高,因为必须创建一个新的矩阵结构,并有足够的空间来容纳新的行/列,并且必须将现有结构复制到新的矩阵结构中。
那么你应该使用哪一个? 大多数情况下,邻接表是正确的方法。 以下是两者之间更详细的比较。
设 V 是图中点的数量,E 是边数。 然后我们有:
| 操作 | 邻接列表 | 邻接矩阵 |
|---|---|---|
| 存储空间 | O(V + E) | O(V^2) |
| 添加点 | O(1) | O(V^2) |
| Add Edge | O(1) | O(1) |
| 添加边 | O(1) | O(1) |
| 检查邻接 | O(V) | O(1) |
“检查邻接”意味着我们试图确定给定点是另一个点的直接邻居。 检查邻接表的邻接的时间是 O(V),因为在最坏的情况下,点需要连接到每个其他点。
在稀疏图的情况下,每个点仅链接到少数其他点,邻接表是存储边的最佳方式。 如果图是密集的,其中每个点连接到大多数其他点,则优选矩阵。
以下是邻接表和邻接矩阵的示例实现:
代码:边和点
每个点的邻接表由Edge对象组成:
public struct Edge<T>: Equatable where T: Equatable, T: Hashable {
public let from: Vertex<T>
public let to: Vertex<T>
public let weight: Double?
}此结构描述了“from”和“to”点以及权重值。 请注意,Edge对象始终是有向的,单向连接(如上图中的箭头所示)。 如果需要无向连接,还需要在相反方向添加Edge对象。 每个Edge可选地存储权重,因此它们可用于描述权重和无权重图。
Vertex看起来像这样:
public struct Vertex<T>: Equatable where T: Equatable, T: Hashable {
public var data: T
public let index: Int
}它存储了一个可以表示任意数据泛型T,它是Hashable以强制唯一性,还有Equatable。 点本身也是Equatable。
代码:图
注意: 有很多方法可以实现图。 这里给出的代码只是一种可能的实现。 您可能希望根据为您尝试解决的每个问题定制图代码。 例如,您的边可能不需要weight属性,或者您可能不需要区分有向边和无向边。这是简单图的例子:
我们可以将其表示为邻接矩阵或邻接表。 实现这些概念的类都从AbstractGraph继承了一个通用API,因此它们可以以相同的方式创建,在幕后具有不同的优化数据结构。
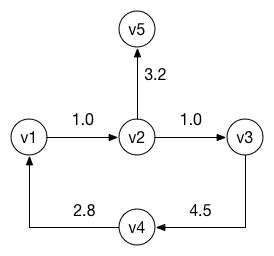
让我们使用每个表示创建一些有向权重图来存储示例:
for graph in [AdjacencyMatrixGraph<Int>(), AdjacencyListGraph<Int>()] {
let v1 = graph.createVertex(1)
let v2 = graph.createVertex(2)
let v3 = graph.createVertex(3)
let v4 = graph.createVertex(4)
let v5 = graph.createVertex(5)
graph.addDirectedEdge(v1, to: v2, withWeight: 1.0)
graph.addDirectedEdge(v2, to: v3, withWeight: 1.0)
graph.addDirectedEdge(v3, to: v4, withWeight: 4.5)
graph.addDirectedEdge(v4, to: v1, withWeight: 2.8)
graph.addDirectedEdge(v2, to: v5, withWeight: 3.2)
}如前所述,要创建无向边,您需要制作两个有向边。 对于无向图,我们改为使用以下方法:
graph.addUndirectedEdge(v1, to: v2, withWeight: 1.0)
graph.addUndirectedEdge(v2, to: v3, withWeight: 1.0)
graph.addUndirectedEdge(v3, to: v4, withWeight: 4.5)
graph.addUndirectedEdge(v4, to: v1, withWeight: 2.8)
graph.addUndirectedEdge(v2, to: v5, withWeight: 3.2)在任何一种情况下,我们都可以提供nil作为withWeight参数的值来制作无权重图。
代码:邻接表
为了维护邻接表,有一个类将边列表映射到点。 该图只是维护这些对象的数组,并根据需要修改它们。
private class EdgeList<T> where T: Equatable, T: Hashable {
var vertex: Vertex<T>
var edges: [Edge<T>]? = nil
init(vertex: Vertex<T>) {
self.vertex = vertex
}
func addEdge(_ edge: Edge<T>) {
edges?.append(edge)
}
}它们被实现为一个类而不是结构,所以我们可以通过引用来修改它们,就像将边添加到新点一样,源点已经有一个边列表:
open override func createVertex(_ data: T) -> Vertex<T> {
// check if the vertex already exists
let matchingVertices = vertices.filter() { vertex in
return vertex.data == data
}
if matchingVertices.count > 0 {
return matchingVertices.last!
}
// if the vertex doesn't exist, create a new one
let vertex = Vertex(data: data, index: adjacencyList.count)
adjacencyList.append(EdgeList(vertex: vertex))
return vertex
}该示例的邻接表如下所示:
v1 -> [(v2: 1.0)]
v2 -> [(v3: 1.0), (v5: 3.2)]
v3 -> [(v4: 4.5)]
v4 -> [(v1: 2.8)]一般形式a -> [(b: w), ...],表示从a到b的边是存在的,权重为w(可能有更多a出去的边)。
代码:邻接矩阵
我们将在二维[[Double?]]数组中追踪邻接矩阵。 nil表示没有边,而任何其他值表示给定权重的边。 如果adjacencyMatrix[i][j]不是nil,则从点i到点j有一条边。
要使用点索引矩阵,我们使用Vertex中的index属性,该属性是在通过图对象创建点时分配的。 创建新点时,图必须调整矩阵的大小:
open override func createVertex(_ data: T) -> Vertex<T> {
// check if the vertex already exists
let matchingVertices = vertices.filter() { vertex in
return vertex.data == data
}
if matchingVertices.count > 0 {
return matchingVertices.last!
}
// if the vertex doesn't exist, create a new one
let vertex = Vertex(data: data, index: adjacencyMatrix.count)
// Expand each existing row to the right one column.
for i in 0 ..< adjacencyMatrix.count {
adjacencyMatrix[i].append(nil)
}
// Add one new row at the bottom.
let newRow = [Double?](repeating: nil, count: adjacencyMatrix.count + 1)
adjacencyMatrix.append(newRow)
_vertices.append(vertex)
return vertex
}然后邻接矩阵看起来像这样:
[[nil, 1.0, nil, nil, nil] v1
[nil, nil, 1.0, nil, 3.2] v2
[nil, nil, nil, 4.5, nil] v3
[2.8, nil, nil, nil, nil] v4
[nil, nil, nil, nil, nil]] v5
v1 v2 v3 v4 v5
扩展阅读
本文描述了图是什么,以及如何实现基本数据结构。 我们还有关于图实际用途的其他文章,所以也要查看一下!
广度优先搜索(BFS,Breadth-First Search)
这个话题已经有个辅导文章
广度优先搜索(BFS,Breadth-First Search)是用于遍历、搜索树或图数据结构的算法。它从源节点开始,在移动到下一级邻居之前首先探索直接邻居节点。
广度优先搜索可以用于有向图和无向图。
动画示例
以下是广度优先搜索在图上的工作原理:
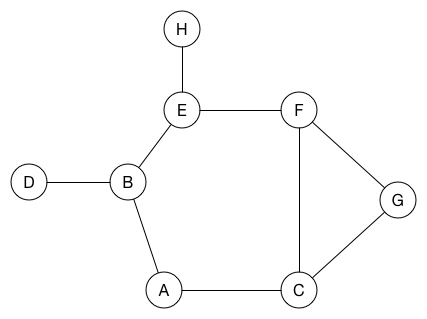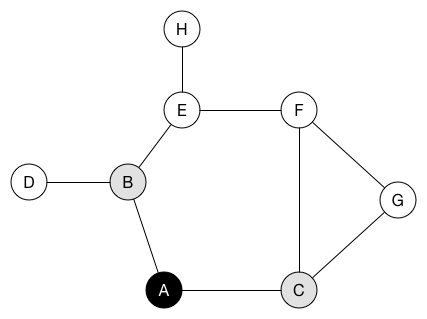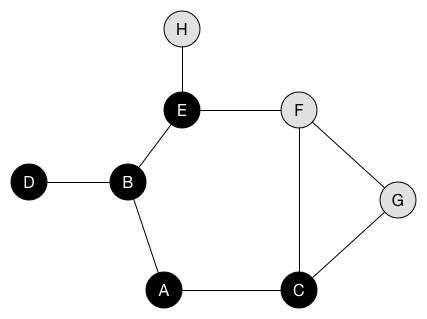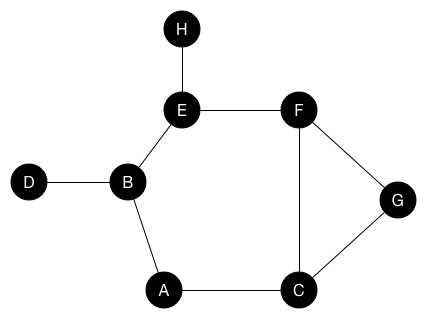
当我们访问节点时,将其着色为黑色。 还将其邻居节点放入队列。 在动画中,入队但尚未访问的节点以灰色显示。
让我们按照动画示例进行操作。 我们从源节点A开始,并将其添加到队列中。 在动画中,这显示为节点A变为灰色。
queue.enqueue(A)队列现在是[A]。 我们的想法是,只要队列中有节点,我们就会访问位于队列前端的节点,如果尚未访问它们,则将其相邻的邻居节点入队。
要开始遍历图,我们将第一个节点从队列中推出A,并将其着色为黑色。 然后我们将它的两个邻居节点B和C入队。 它们的颜色变成灰色。
queue.dequeue() // A
queue.enqueue(B)
queue.enqueue(C)队列现在是[B, C]。 我们将B出列,并将B的邻居节点D和E排入队列。
queue.dequeue() // B
queue.enqueue(D)
queue.enqueue(E)队列现在是[C, D, E]。 将C出列,并将C的邻居节点F和G入队。
queue.dequeue() // C
queue.enqueue(F)
queue.enqueue(G)队列现在是[D, E, F, G]。 出列D,它没有邻居节点。
queue.dequeue() // D队列现在是[E, F, G]。 将E出列并将其单个邻居节点H排队。 注意B也是E的邻居,但我们已经访问了B,所以我们不再将它添加到队列中。
queue.dequeue() // E
queue.enqueue(H)队列现在是[F, G, H]。 出队F,它没有未访问的邻居节点。
queue.dequeue() // F队列现在是[G, H]。 出列G,它没有未访问的邻居节点。
queue.dequeue() // G队列现在是[H]。 出列H,它没有未访问的邻居节点。
queue.dequeue() // H队列现在为空,这意味着已经探索了所有节点。 探索节点的顺序是A,B,C,D,E,F,G,H。
我们可以将其显示为树:
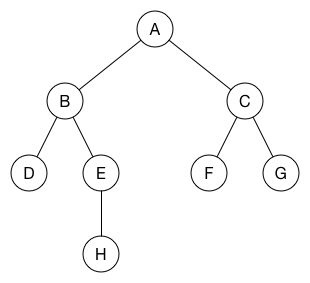
节点的父节点是"发现"该节点的节点。 树的根是广度优先搜索开始的节点。
对于未加权的图,此树定义从起始节点到树中每个其他节点的最短路径。 广度优先搜索是在图中找到两个节点之间的最短路径的一种方法。
代码
使用队列简单实现广度优先搜索:
func breadthFirstSearch(_ graph: Graph, source: Node) -> [String] {
var queue = Queue<Node>()
queue.enqueue(source)
var nodesExplored = [source.label]
source.visited = true
while let node = queue.dequeue() {
for edge in node.neighbors {
let neighborNode = edge.neighbor
if !neighborNode.visited {
queue.enqueue(neighborNode)
neighborNode.visited = true
nodesExplored.append(neighborNode.label)
}
}
}
return nodesExplored
}虽然队列中有节点,但我们访问第一个节点,然后将其尚未被访问的直接邻居节点入队。
将此代码放在 playground中, 并进行如下测试:
let graph = Graph()
let nodeA = graph.addNode("a")
let nodeB = graph.addNode("b")
let nodeC = graph.addNode("c")
let nodeD = graph.addNode("d")
let nodeE = graph.addNode("e")
let nodeF = graph.addNode("f")
let nodeG = graph.addNode("g")
let nodeH = graph.addNode("h")
graph.addEdge(nodeA, neighbor: nodeB)
graph.addEdge(nodeA, neighbor: nodeC)
graph.addEdge(nodeB, neighbor: nodeD)
graph.addEdge(nodeB, neighbor: nodeE)
graph.addEdge(nodeC, neighbor: nodeF)
graph.addEdge(nodeC, neighbor: nodeG)
graph.addEdge(nodeE, neighbor: nodeH)
graph.addEdge(nodeE, neighbor: nodeF)
graph.addEdge(nodeF, neighbor: nodeG)
let nodesExplored = breadthFirstSearch(graph, source: nodeA)
print(nodesExplored)结果输出: ["a", "b", "c", "d", "e", "f", "g", "h"]
BFS有什么用?
广度优先搜索可用于解决许多问题。 例如:
深度优先搜索(DFS,Depth-First Search)
这个主题已经有辅导文章
深度优先搜索(DFS)是用于遍历或搜索树或图数据结构的算法。它从源节点开始,并在回溯之前尽可能地沿着每个分支进行探索。
深度优先搜索可以用于有向图和无向图。
动画示例
以下是深度优先搜索在图上的工作方式:
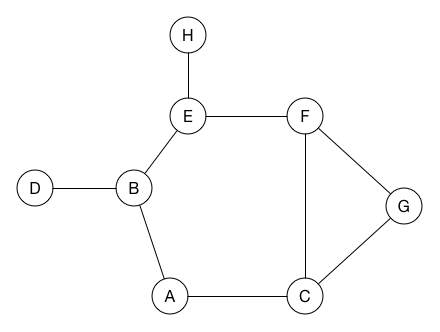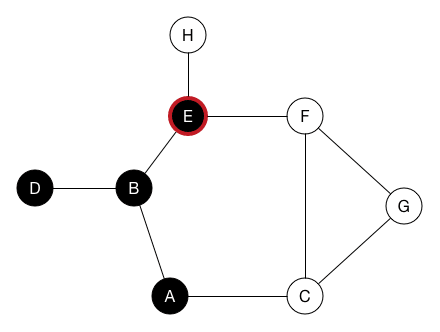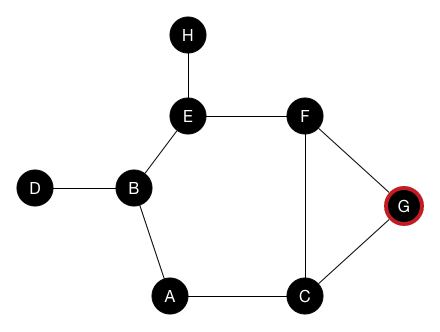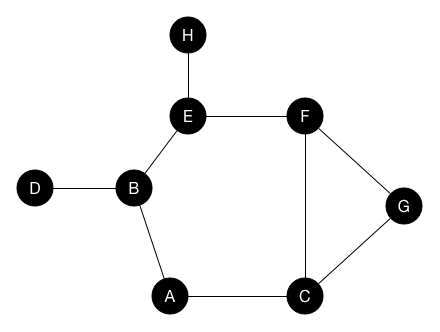
假设我们从节点A开始搜索。 在深度优先搜索中,我们查看起始节点的第一个邻居并访问它,在这个示例中是节点B。然后我们查找节点B的第一个邻居并访问它,它是节点D。由于D没有自己的任何未访问的邻居节点,我们回溯到节点B并转到其另外的邻居节点E。依此类推,直到我们访问了图中的所有节点。
每当我们访问第一个邻居节点并继续前进,直到无处可去,然后我们回溯到之前访问的节点。 当我们一直回溯到节点A时,搜索就完成了。
对于上面的例子,是按照A,B,D,E,H,F,G,C的顺序访问节点的。
深度优先搜索过程也可以显示为树:
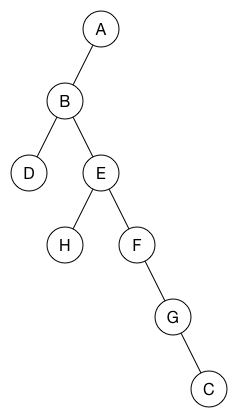
节点的父节点是“发现”该节点的节点。 树的根是您开始深度优先搜索的节点。 每当有一个分支时,那就是我们回溯的地方。
代码
深度优先搜索的简单递归实现:
func depthFirstSearch(_ graph: Graph, source: Node) -> [String] {
var nodesExplored = [source.label]
source.visited = true
for edge in source.neighbors {
if !edge.neighbor.visited {
nodesExplored += depthFirstSearch(graph, source: edge.neighbor)
}
}
return nodesExplored
}广度优先搜索首先访问所有直接邻居,而深度优先搜索尝试尽可能地深入树或图。
在 playground 里测试:
let graph = Graph()
let nodeA = graph.addNode("a")
let nodeB = graph.addNode("b")
let nodeC = graph.addNode("c")
let nodeD = graph.addNode("d")
let nodeE = graph.addNode("e")
let nodeF = graph.addNode("f")
let nodeG = graph.addNode("g")
let nodeH = graph.addNode("h")
graph.addEdge(nodeA, neighbor: nodeB)
graph.addEdge(nodeA, neighbor: nodeC)
graph.addEdge(nodeB, neighbor: nodeD)
graph.addEdge(nodeB, neighbor: nodeE)
graph.addEdge(nodeC, neighbor: nodeF)
graph.addEdge(nodeC, neighbor: nodeG)
graph.addEdge(nodeE, neighbor: nodeH)
graph.addEdge(nodeE, neighbor: nodeF)
graph.addEdge(nodeF, neighbor: nodeG)
let nodesExplored = depthFirstSearch(graph, source: nodeA)
print(nodesExplored)打印结果是: ["a", "b", "d", "e", "h", "f", "g", "c"]
DFS有什么用?
深度优先搜索可用于解决许多问题,例如:
最短路径算法(Shortest Path (Unweighted Graph))
目标:找到图中从一个节点到另一个节点的最短路径。
假设我们以下图为例:

我们可能想知道从节点A到节点F的最短路径是什么。
如果图是未加权的,那么找到最短路径很容易:我们可以使用广度优先搜索算法。 对于加权图,我们可以使用Dijkstra算法。
未加权图:广度优先搜索
广度优先搜索是遍历树或图数据结构的方法。 它从源节点开始,在移动到下一级邻居之前首先探索直接邻居节点。 方便的副作用是,它会自动计算源节点与树或图中其他每个节点之间的最短路径。
广度优先搜索的结果可以用树表示:
树的根节点是广度优先搜索开始的节点。 为了找到从节点A到任何其他节点的距离,我们只计算树中边的数目。 所以我们发现A和F之间的最短路径是2.树不仅告诉你路径有多长,而且还告诉你如何实际从A到F(或者任何一个其他节点)。
让我们将广度优先搜索付诸实践,并计算从A到所有其他节点的最短路径。 我们从源节点A开始,并将其添加到队列中,距离为0。
queue.enqueue(element: A)
A.distance = 0队列现在是[A]。 我们将A出列并将其两个直接邻居节点B和C入列,并设置距离1。
queue.dequeue() // A
queue.enqueue(element: B)
B.distance = A.distance + 1 // result: 1
queue.enqueue(element: C)
C.distance = A.distance + 1 // result: 1队列现在是[B, C]。 将B出列,并将B的邻居节点D和E入列,距离为2。
queue.dequeue() // B
queue.enqueue(element: D)
D.distance = B.distance + 1 // result: 2
queue.enqueue(element: E)
E.distance = B.distance + 1 // result: 2队列现在是[C, D, E]。 将C出列并将C的邻居节点F和G入队,距离为2。
queue.dequeue() // C
queue.enqueue(element: F)
F.distance = C.distance + 1 // result: 2
queue.enqueue(element: G)
G.distance = C.distance + 1 // result: 2这么一直持续到队列为空,同时我们访问了所有节点。 每次我们发现一个新节点时,它会获得其父节点的distance加1.正如您所看到的,这正是广度优先搜索算法的作用, 除此之外,我们现在还知道距离寻找的路径。
这是代码:
func breadthFirstSearchShortestPath(graph: Graph, source: Node) -> Graph {
let shortestPathGraph = graph.duplicate()
var queue = Queue<Node>()
let sourceInShortestPathsGraph = shortestPathGraph.findNodeWithLabel(label: source.label)
queue.enqueue(element: sourceInShortestPathsGraph)
sourceInShortestPathsGraph.distance = 0
while let current = queue.dequeue() {
for edge in current.neighbors {
let neighborNode = edge.neighbor
if !neighborNode.hasDistance {
queue.enqueue(element: neighborNode)
neighborNode.distance = current.distance! + 1
}
}
}
return shortestPathGraph
}在playground中进行测试:
let shortestPathGraph = breadthFirstSearchShortestPath(graph: graph, source: nodeA)
print(shortestPathGraph.nodes)输出结果:
Node(label: a, distance: 0), Node(label: b, distance: 1), Node(label: c, distance: 1),
Node(label: d, distance: 2), Node(label: e, distance: 2), Node(label: f, distance: 2),
Node(label: g, distance: 2), Node(label: h, distance: 3)注意:这个版本的breadthFirstSearchShortestPath()实际上并不生成树,它只计算距离。 有关如何通过去除边缘将图转换为树,请参见最小生成树/)。
最小生成树(未加权图)(Minimum Spanning Tree (Unweighted Graph))
最小生成树描述了包含访问图中每个节点所需的最小数目边的路径。
看下图:
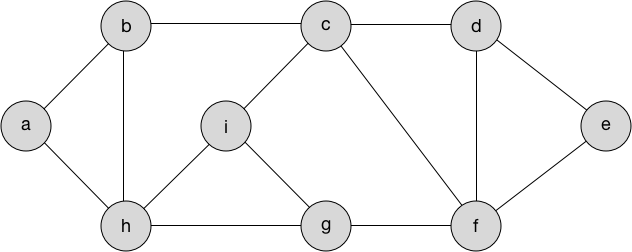
如果我们从节点a开始并想要访问每个其他节点,那么最有效的路径是什么? 我们可以使用最小生成树算法来计算它。
这是图的最小生成树。 它由粗体边表示:
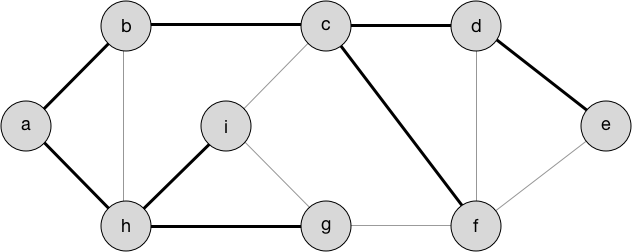
绘制为更一般形式的树,它看起来像这样:
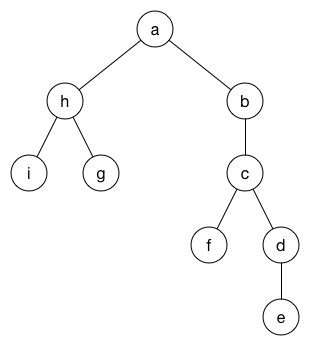
要计算未加权图上的最小生成树,我们可以使用广度优先搜索 算法。广度优先搜索从源节点开始,并在移动到下一级邻居之前首先通过探索直接邻居节点来遍历图。如果我们通过选择性地删除边来调整此算法,那么它可以将图转换为最小生成树。
让我们逐步完成这个例子。 我们从源节点a开始,将其添加到队列中并将其标记为已访问。
queue.enqueue(a)
a.visited = true队列现在是[a]。 与广度优先搜索一样,我们将队列前面的节点a出队,并将其直接邻居节点b和h入队。 将它们标记为访问过。
queue.dequeue() // a
queue.enqueue(b)
b.visited = true
queue.enqueue(h)
h.visited = true队列现在是[b, h]。 将b出队并将邻居节点c入队。 将其标记为已访问。 将b到h边移除,因为已经访问过h。
queue.dequeue() // b
queue.enqueue(c)
c.visited = true
b.removeEdgeTo(h)队列现在是[h, c]。 将h出队并将邻居节点g和i入队,并将它们标记为已访问。
queue.dequeue() // h
queue.enqueue(g)
g.visited = true
queue.enqueue(i)
i.visited = true队列现在是[c, g, i]。 将c出队并将邻居节点d和f入队,并将它们标记为已访问。 删除c和i之间的边,因为已经访问了i。
queue.dequeue() // c
queue.enqueue(d)
d.visited = true
queue.enqueue(f)
f.visited = true
c.removeEdgeTo(i)队列现在是[g, i, d, f]。 出队g。 它的所有邻居都已经被发现了,所以没有什么可以入队的。 删除g到f的边,以及g到i的边,因为已经发现了f和i。
queue.dequeue() // g
g.removeEdgeTo(f)
g.removeEdgeTo(i)队列现在是[i, d, f]。 出队i。 这个节点没有别的办法。
queue.dequeue() // i队列现在是[d, f]。 将d出队并将邻居节点e入队。 将其标记为已访问。 删除d到f的边,因为已经访问了f。
queue.dequeue() // d
queue.enqueue(e)
e.visited = true
d.removeEdgeTo(f)队列现在是[f, e]。 出列f。 删除f和e之间的边,因为已经访问过e。
queue.dequeue() // f
f.removeEdgeTo(e)队列现在是[e]。 出队e。
queue.dequeue() // e队列为空,这意味着已计算出最小生成树。
代码如下:
func breadthFirstSearchMinimumSpanningTree(graph: Graph, source: Node) -> Graph {
let minimumSpanningTree = graph.duplicate()
var queue = Queue<Node>()
let sourceInMinimumSpanningTree = minimumSpanningTree.findNodeWithLabel(source.label)
queue.enqueue(sourceInMinimumSpanningTree)
sourceInMinimumSpanningTree.visited = true
while let current = queue.dequeue() {
for edge in current.neighbors {
let neighborNode = edge.neighbor
if !neighborNode.visited {
neighborNode.visited = true
queue.enqueue(neighborNode)
} else {
current.remove(edge)
}
}
}
return minimumSpanningTree
}此函数返回一个新的Graph对象,该对象仅描述最小生成树。 在图中,这将是仅包含粗体边的图。
将此代码放在playground上,进行测试:
let graph = Graph()
let nodeA = graph.addNode("a")
let nodeB = graph.addNode("b")
let nodeC = graph.addNode("c")
let nodeD = graph.addNode("d")
let nodeE = graph.addNode("e")
let nodeF = graph.addNode("f")
let nodeG = graph.addNode("g")
let nodeH = graph.addNode("h")
let nodeI = graph.addNode("i")
graph.addEdge(nodeA, neighbor: nodeB)
graph.addEdge(nodeA, neighbor: nodeH)
graph.addEdge(nodeB, neighbor: nodeA)
graph.addEdge(nodeB, neighbor: nodeC)
graph.addEdge(nodeB, neighbor: nodeH)
graph.addEdge(nodeC, neighbor: nodeB)
graph.addEdge(nodeC, neighbor: nodeD)
graph.addEdge(nodeC, neighbor: nodeF)
graph.addEdge(nodeC, neighbor: nodeI)
graph.addEdge(nodeD, neighbor: nodeC)
graph.addEdge(nodeD, neighbor: nodeE)
graph.addEdge(nodeD, neighbor: nodeF)
graph.addEdge(nodeE, neighbor: nodeD)
graph.addEdge(nodeE, neighbor: nodeF)
graph.addEdge(nodeF, neighbor: nodeC)
graph.addEdge(nodeF, neighbor: nodeD)
graph.addEdge(nodeF, neighbor: nodeE)
graph.addEdge(nodeF, neighbor: nodeG)
graph.addEdge(nodeG, neighbor: nodeF)
graph.addEdge(nodeG, neighbor: nodeH)
graph.addEdge(nodeG, neighbor: nodeI)
graph.addEdge(nodeH, neighbor: nodeA)
graph.addEdge(nodeH, neighbor: nodeB)
graph.addEdge(nodeH, neighbor: nodeG)
graph.addEdge(nodeH, neighbor: nodeI)
graph.addEdge(nodeI, neighbor: nodeC)
graph.addEdge(nodeI, neighbor: nodeG)
graph.addEdge(nodeI, neighbor: nodeH)
let minimumSpanningTree = breadthFirstSearchMinimumSpanningTree(graph, source: nodeA)
print(minimumSpanningTree) // [node: a edges: ["b", "h"]]
// [node: b edges: ["c"]]
// [node: c edges: ["d", "f"]]
// [node: d edges: ["e"]]
// [node: h edges: ["g", "i"]]注意: 在未加权的图上,任何生成树始终是最小生成树。 这意味着您还可以使用深度优先搜索来查找最小生成树。