集合
布隆过滤器(Bloom Filter)
介绍
布隆过滤器是一种节省空间的数据结构,可以告诉您元素是否存在于集合中。
这是一个概率数据结构:对布隆过滤器的查询返回false,意味着该元素肯定不在集合中,或者是true,这意味着元素可能在集合中。
误报的可能性很小,即使查询返回true,元素实际上也可能不在集合中。 但是永远不会有任何漏报:如果查询返回false,你可以保证,那么元素确实不在集合中。
所以布隆过滤器告诉你,“绝对不是”或“可能是的”。
起初,这似乎不太有用。 但是,它在缓存过滤和数据同步等应用程序中很重要。
布隆过滤器优于哈希表的一个优点是前者保持恒定的内存使用和恒定时间插入和搜索。 对于具有大量元素的集合,哈希表和布隆过滤器之间的性能差异很大,如果您不需要保证不存在误报,则它是可行的选项。
注意:与哈希表不同,布隆过滤器不存储实际对象。 它只会记住你看过的对象(有一定程度的不确定性)以及你没有看过的对象。
将对象插入集合中
布隆过滤器本质上是一个固定长度的位向量,一个位数组。 当我们插入对象时,我们将其中一些位设置为1,当我们查询对象时,我们检查某些位是0还是1。 两个操作都使用哈希函数。
要在过滤器中插入元素,可以使用多个不同的哈希函数对元素进行哈希。 每个哈希函数返回一个我们映射到数组中索引的值。 然后,我们将这些索引处的位设置为1或true。
例如,假设这是我们的位数组。 我们有17位,最初它们都是0或false:
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 ]现在我们要在布隆过滤器中插入字符串"Hello world!"。 我们对此字符串应用两个哈希函数。第一个给出值1999532104120917762。我们通过取数组长度的模数将此哈希值映射到数组的索引:1999532104120917762 % 17 = 4。 这意味着我们将索引4处的位设置为1或者true:
[ 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 ]然后我们再次散列原始字符串,但这次使用不同的散列函数。 它给出哈希值9211818684948223801。取17的模数为12,我们也将索引12处的位设置为1:
[ 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0 ]这两个1位足以告诉布隆过滤器它现在包含字符串 "Hello world!"。 当然,它不包含实际的字符串,所以你不能要求布隆过滤器,“给我一个你包含的所有对象的列表”。 所有它都是一堆1和0。
查询集合
类似于插入,查询是通过首先对期望值进行哈希来实现的,该期望值给出几个数组索引,然后检查这些索引处的所有位是否为1。 如果其中一个位不是1,则无法插入该元素,并且查询返回false。 如果所有位都是1,则查询返回true。
例如,如果我们查询字符串"Hello WORLD",那么第一个哈希函数返回5383892684077141175,其中取17的模是12。该位是1。但是第二个哈希函数给出5625257205398334446,它映射到数组索引9。该位为0。 这意味着字符串"Hello WORLD"不在过滤器中,查询返回false。
第一个哈希函数映射到1位的事实是巧合(它与两个字符串以"Hello "开头的事实无关)。 太多这样的巧合可能导致“碰撞”。 如果存在冲突,即使未插入元素,查询也可能错误地返回true - 导致前面提到的误报问题。
假设我们插入了一些其他元素,"Bloom Filterz",它设置了第7位和第9位。现在数组看起来像这样:
[ 0, 0, 0, 0, 1, 0, 0, 1, 0, 1, 0, 0, 1, 0, 0, 0, 0 ]如果再次查询"Hello WORLD",则过滤器会看到第12位为true,第9位现在也为true。 它报告说"Hello WORLD"确实出现在集合中,即使它不是......因为我们从未插入过那个特定的字符串。这是误报。这个例子说明了为什么布隆过滤器永远不会说“绝对是”,只有“可能是”。
您可以通过使用具有更多位的数组并使用其他哈希函数来解决此类问题。 当然,使用的哈希函数越多,布隆过滤器就越慢。 所以你必须取得平衡。
使用布隆过滤器无法删除,因为任何一个位都可能属于多个元素。 一旦你添加了一个元素,它就在那里。
布隆过滤器的性能是O(k),其中 k是哈希函数的数量。
代码
代码非常简单。 内部位数组在初始化时设置为固定长度,初始化后不能进行突变。
public init(size: Int = 1024, hashFunctions: [(T) -> Int]) {
self.array = [Bool](repeating: false, count: size)
self.hashFunctions = hashFunctions
}应在初始化时指定几个哈希函数。 您使用哪些哈希函数将取决于您将添加到集合的元素的数据类型。 你可以在playground测试中看到一些例子 - 字符串的djb2和sdbm哈希函数。
插入只是将所需的位翻转为true:
public func insert(_ element: T) {
for hashValue in computeHashes(element) {
array[hashValue] = true
}
}这使用computeHashes()函数,它循环遍历指定的hashFunctions并返回索引数组:
private func computeHashes(_ value: T) -> [Int] {
return hashFunctions.map() { hashFunc in abs(hashFunc(value) % array.count) }
}并查询检查以确保哈希值处的位为true:
public func query(_ value: T) -> Bool {
let hashValues = computeHashes(value)
let results = hashValues.map() { hashValue in array[hashValue] }
let exists = results.reduce(true, { $0 && $1 })
return exists
}如果你来自另一种命令式语言,你可能会注意到exists赋值中的不寻常语法。 当Swift使代码更加简洁和可读时,Swift使用函数范例,在这种情况下,reduce是一种更加简洁的方法来检查所有必需的位是否为true而不是用for循环。
哈希集合(Hash Set)
集合是元素的集合,有点像数组但有两个重要的区别:集合中元素的顺序不重要,每个元素只能出现一次。
如果以下是数组,它们都会有所不同。 但是,它们都代表相同的集合:
[1 ,2, 3]
[2, 1, 3]
[3, 2, 1]
[1, 2, 2, 3, 1]因为每个元素只能出现一次,所以将元素写入的次数并不重要 —— 只有其中一个元素有效。
注意:当我有一组对象但不关心它们的顺序时,我经常更喜欢使用数组上的集合。使用集合与程序员通信,元素的顺序并不重要。 如果你正在使用数组,那么你不能假设同样的事情。
典型集合操作:
插入元素
删除元素
检查集合是否包含元素
与另一组合并
与另一组交叉
计算与另一组的差异
并集,交集和差集是将两个集合组合成一个集合的方法:
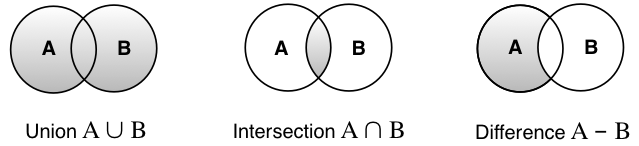
从Swift 1.2开始,标准库包含一个内置的Set类型,但在这里我将展示如何制作自己的类型。您不会在生产代码中使用它,但了解如何实现集合是有益的。
使用简单数组实现集合是可能的,但这不是最有效的方法。 相反,我们将使用字典。由于Swift的字典是使用哈希表构建的,因此我们自己的集合将是一个哈希集。
代码
以下是Swift中HashSet的开头:
public struct HashSet<T: Hashable> {
fileprivate var dictionary = Dictionary<T, Bool>()
public init() {
}
public mutating func insert(_ element: T) {
dictionary[element] = true
}
public mutating func remove(_ element: T) {
dictionary[element] = nil
}
public func contains(_ element: T) -> Bool {
return dictionary[element] != nil
}
public func allElements() -> [T] {
return Array(dictionary.keys)
}
public var count: Int {
return dictionary.count
}
public var isEmpty: Bool {
return dictionary.isEmpty
}
}代码非常简单,因为我们依靠Swift的内置Dictionary来完成所有的艰苦工作。 我们使用字典的原因是字典键必须是唯一的,就像集合中的元素一样。 此外,字典在其大多数操作中具有O(1)时间复杂度,使得该集合实现非常快。
因为我们使用的是字典,所以通用类型T必须符合Hashable。 您可以将任何类型的对象放入我们的集合中,只要它可以进行哈希处理即可。 (对于Swift自己的Set也是如此。)
通常,您使用字典将键与值关联,但对于一个集合,我们只关心键。 这就是为什么我们使用Bool作为字典的值类型,即使我们只将它设置为true,而不是false。 (我们本可以选择任何东西,但布尔占用的空间最小。)
将代码复制到 playground 并添加一些测试:
var set = HashSet<String>()
set.insert("one")
set.insert("two")
set.insert("three")
set.allElements() // ["one, "three", "two"]
set.insert("two")
set.allElements() // still ["one, "three", "two"]
set.contains("one") // true
set.remove("one")
set.contains("one") // falseallElements()函数将集合的内容转换为数组。请注意,该数组中元素的顺序可能与添加项目的顺序不同。正如我所说,一个集合并不关心元素的顺序(也不是字典)。
合并集合
集合的很多用处在于如何合并它们。(如果你曾经使用像Sketch或Illustrator这样的矢量绘图程序,你会看到Union,Subtract,Intersect选项来组合形状。这边也是同样的事情。)
这是union操作的代码:
extension HashSet {
public func union(_ otherSet: HashSet<T>) -> HashSet<T> {
var combined = HashSet<T>()
for obj in self.dictionary.keys {
combined.insert(obj)
}
for obj in otherSet.dictionary.keys {
combined.insert(obj)
}
return combined
}
}两个集合的 union 创建一个新集合,它由集合A中的所有元素加上集合B中的所有元素组成。当然,如果存在重复元素,它们只计算一次。
示例:
var setA = HashSet<Int>()
setA.insert(1)
setA.insert(2)
setA.insert(3)
setA.insert(4)
var setB = HashSet<Int>()
setB.insert(3)
setB.insert(4)
setB.insert(5)
setB.insert(6)
let union = setA.union(setB)
union.allElements() // [5, 6, 2, 3, 1, 4]如您所见,两个集合的并集现在包含所有元素。 值3和4仍然只出现一次,即使它们都在两组中。
两个集合的intersection仅包含它们共有的元素。 这是代码:
extension HashSet {
public func intersect(_ otherSet: HashSet<T>) -> HashSet<T> {
var common = HashSet<T>()
for obj in dictionary.keys {
if otherSet.contains(obj) {
common.insert(obj)
}
}
return common
}
}测试:
let intersection = setA.intersect(setB)
intersection.allElements()这打印 [3, 4] 因为那些是集合A中也是集合B的唯一对象。
最后,两组之间的difference删除了它们共有的元素。 代码如下:
extension HashSet {
public func difference(_ otherSet: HashSet<T>) -> HashSet<T> {
var diff = HashSet<T>()
for obj in dictionary.keys {
if !otherSet.contains(obj) {
diff.insert(obj)
}
}
return diff
}
}它实际上与intersect()相反。 试试看:
let difference1 = setA.difference(setB)
difference1.allElements() // [2, 1]
let difference2 = setB.difference(setA)
difference2.allElements() // [5, 6]Where to go from here?
如果你看一下Swift自己的Set的文档,你会发现它有更多的功能。 一个明显的扩展是使HashSet符合SequenceType,这样你就可以用for ...in循环迭代它。
您可以做的另一件事是将Dictionary替换为实际的哈希表,但是只存储键并且不将它们与任何东西相关联。 所以你不再需要Bool值了。
如果您经常需要查找元素是否属于集合并执行并集,那么并查集数据结构可能更合适。它使用树结构而不是字典来使查找和并集操作非常有效。
注意:我想让HashSet符合ArrayLiteralConvertible,这样你就可以编写let setA: HashSet<Int> = [1, 2, 3, 4]但是目前这会使编译器崩溃。
多重集合(Multiset)
多重集合(也称为bag,简称多重集)是一种类似于常规集的数据结构,但它可以存储同一元素的多个实例。
例如,如果我将元素1,2,2添加到常规集中,则该集将仅包含两个项,因为第二次添加2无效。
var set = Set<Int>()
set.add(1) // set is now [1]
set.add(2) // set is now [1, 2]
set.add(2) // set is still [1, 2]相比之下,在将元素1,2,2添加到多重集之后,它将包含三个项目。
var set = Multiset<Int>()
set.add(1) // set is now [1]
set.add(2) // set is now [1, 2]
set.add(2) // set is now [1, 2, 2]你可能会认为这看起来很像一个数组。 那你为什么要用多重集呢? 让我们考虑两者之间的差异......
排序:数组维护添加到它们的项目的顺序,多重集合没有
测试成员资格:测试元素是否其成员,数组是O(N),而多重集合的O(1)。
测试子集:测试集合X是否是集合Y的子集,对于多重集而言是一个简单的操作,但对于数组来说是复杂的
多重集的典型操作是:
添加元素
删除元素
获取元素的计数(添加的次数)
获取整个集合的计数(已添加的项数)
检查它是否是另一个多重集的子集
在实际使用中,可使用多重集合来确定一个字符串是否是另一个字符串的部分。例如,“cacti”这个词是“tactical”的部分。(换句话说,我可以重新整理“tactical”字母来得到“cacti”,以及余下的一些字母。)
var cacti = Multiset<Character>("cacti")
var tactical = Multiset<Character>("tactical")
cacti.isSubSet(of: tactical) // true!实施
在幕后,Multiset的实现使用字典来存储元素到它们被添加的次数的映射。
这是它的本质:
public struct Multiset<Element: Hashable> {
private var storage: [Element: UInt] = [:]
public init() {}以下是如何使用此类创建多重集的字符串:
var set = Multiset<String>()添加元素是递增该元素的计数器,或者如果它尚不存在则将其设置为1:
public mutating func add (_ elem: Element) {
storage[elem, default: 0] += 1
}以下是使用此方法添加到我们之前创建的集合的方法:
set.add("foo")
set.add("foo")
set.allItems // returns ["foo", "foo"]我们的集合现在包含两个元素,字符串“foo”。
删除元素与添加元素的工作方式大致相同; 递减元素的计数器,或者如果在删除之前其值为1,则将其从基础字典中删除。
public mutating func remove (_ elem: Element) {
if let currentCount = storage[elem] {
if currentCount > 1 {
storage[elem] = currentCount - 1
} else {
storage.removeValue(forKey: elem)
}
}
}获取项目的计数很简单:我们只返回内部字典中给定项目的值。
public func count(for key: Element) -> UInt {
return storage[key] ?? 0
}有序集(Ordered Set)
我们来看看苹果如何实现有序集。
Here is the example about how it works
以下是有关其工作原理的示例:
let s = AppleOrderedSet<Int>()
s.add(1)
s.add(2)
s.add(-1)
s.add(0)
s.insert(4, at: 3)
print(s.all()) // [1, 2, -1, 4, 0]
s.set(-1, at: 0) // 已经有-1在index: 2,因此这个操作不做任何事情
print(s.all()) // [1, 2, -1, 4, 0]
s.remove(-1)
print(s.all()) // [1, 2, 4, 0]
print(s.object(at: 1)) // 2
print(s.object(at: 2)) // 4显着的区别是数组没有排序。 插入时,数组中的元素是相同的。 将数组映像为不重复且具有 O(logn) 或 O(1) 搜索时间。
这里的想法是使用数据结构来提供 O(1) 或 O(logn) 时间复杂度,因此很容易考虑哈希表。
var indexOfKey: [T: Int]
var objects: [T]indexOfKey is used to track the index of the element. objects is array holding elements.indexOfKey 用于跟踪元素的索引。 objects是数组保持元素。
我们将在这里详细介绍一些关键功能。
添加
更新indexOfKey并在objects的末尾插入元素
// O(1)
public func add(_ object: T) {
guard indexOfKey[object] == nil else {
return
}
objects.append(object)
indexOfKey[object] = objects.count - 1
}插入
在数组的随机位置插入将花费 O(n) 时间。
// O(n)
public func insert(_ object: T, at index: Int) {
assert(index < objects.count, "Index should be smaller than object count")
assert(index >= 0, "Index should be bigger than 0")
guard indexOfKey[object] == nil else {
return
}
objects.insert(object, at: index)
indexOfKey[object] = index
for i in index+1..<objects.count {
indexOfKey[objects[i]] = i
}
}设置
如果object已存在于OrderedSet中,则什么也不做。 否则,我们需要更新indexOfkey和objects。
// O(1)
public func set(_ object: T, at index: Int) {
assert(index < objects.count, "Index should be smaller than object count")
assert(index >= 0, "Index should be bigger than 0")
guard indexOfKey[object] == nil else {
return
}
indexOfKey.removeValue(forKey: objects[index])
indexOfKey[object] = index
objects[index] = object
}删除
删除数组中的元素将花费 O(n)。 同时,我们需要在删除元素后更新所有元素的索引。
// O(n)
public func remove(_ object: T) {
guard let index = indexOfKey[object] else {
return
}
indexOfKey.removeValue(forKey: object)
objects.remove(at: index)
for i in index..<objects.count {
indexOfKey[objects[i]] = i
}
}